Binary entropy function
In information theory, the binary entropy function, denoted 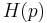 or
or 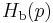 , is defined as the entropy of a Bernoulli trial with probability of success p. Mathematically, the Bernoulli trial is modelled as a random variable X that can take on only two values: 0 and 1. The event
, is defined as the entropy of a Bernoulli trial with probability of success p. Mathematically, the Bernoulli trial is modelled as a random variable X that can take on only two values: 0 and 1. The event 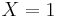 is considered a success and the event
is considered a success and the event 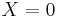 is considered a failure. (These two events are mutually exclusive and exhaustive.)
is considered a failure. (These two events are mutually exclusive and exhaustive.)
If 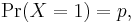 then
then 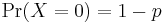 and the entropy of X is given by
and the entropy of X is given by

where 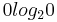 is taken to be 0. The logarithms in this formula are usually taken (as shown in the graph) to the base 2. See binary logarithm.
is taken to be 0. The logarithms in this formula are usually taken (as shown in the graph) to the base 2. See binary logarithm.
When 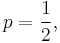 the binary entropy function attains its maximum value. This is the case of the unbiased bit, the most common unit of information entropy.
the binary entropy function attains its maximum value. This is the case of the unbiased bit, the most common unit of information entropy.
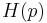 is distinguished from the entropy function by its taking a single scalar constant parameter. For tutorial purposes, in which the reader may not distinguish the appropriate function by its argument,
is distinguished from the entropy function by its taking a single scalar constant parameter. For tutorial purposes, in which the reader may not distinguish the appropriate function by its argument, 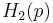 is often used; however, this could confuse this function with the analogous function related to Rényi entropy, so
is often used; however, this could confuse this function with the analogous function related to Rényi entropy, so 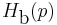 (with "b" not in italics) should be used to dispel ambiguity.
(with "b" not in italics) should be used to dispel ambiguity.
Contents |
Derivative
The derivative of the binary entropy function may be expressed as the negative of the logit function:
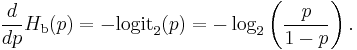
Taylor series
The Taylor series of the binary entropy function in a neighbourhood of 1/2 is
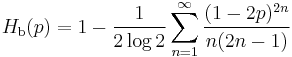
for 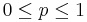
See also
References
- David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1